
In this article we will consider actual problems of formation and operation of Configuration management databases (CMDB), and show the most promising ways to solve them.
Further we will talk about configuration management using CMDB, and not about asset management, although quite often these concepts are not separated.
CMDB and configuration management
CMDB is one of the key elements of Configuration Management, originally conceived as a database that contains information about services, accounted configuration items, and the relationships between these items.
When successfully built and regularly used, CMDB helps to achieve the goals set forth in ITIL:
- controlling all configurations within an organization;
- providing accurate configuration information to support service management processes;
- providing information for incident, problem, change and release management processes;
However, a CMDB is not a database in the usual sense. Most often it is more correct to speak about a set of separated repositories combined into a single model or not combined at all.
Often the situation looks as follows:
- software is managed within one information system;
- software licenses are managed within another information system;
- physical servers, workstations, networking and other equipment are managed within a third;
- cloud infrastructure objects – in yet another system.
Data in such systems are most often presented in different forms, convenient for local management. In this case, to reduce the information to a single data format, convenient for centralized management, or is not possible, or requires significant labor costs.
The quality of management processes is extremely dependent on the relevance of information.
As long as the organization is small, we have the ability to live-stream up-to-date information about our assets and configurations. At some point, however, the organization “outgrows” on-the-fly management, and there is a need for an orderly storage of up-to-date configuration information.
Data Update Challenges in CMDB
The IT industry has changed quite a bit in the last 10 years. With agile approaches to project management, the speed of delivering business value from IT (Time To Value) has increased several times over. Applying DevOps practices can deliver code to productive environments up to 200 times faster than before.
Static infrastructures that were manageable “on paper” or in Excel are giving way to dynamic infrastructures. Virtualization and clouds have made their way into our lives: virtual servers deployed for temporary needs, virtual components moving from one physical host to another, and a host of other changes that are constantly taking place in infrastructure. There is a huge amount of software that is constantly being updated, rolled back and refined.
Each of these changes needs to be tracked and recorded to ensure that you can access up-to-date information
In such conditions, the main problem of CMDB becomes the complexity of updating the information it contains.
These problems stem from the fact that the idea of the CMDB was formed in an era dominated by “ironclad” configuration units. For effective management, a list of infrastructure elements with explanations of what tasks each particular element performs was sufficient.
The idea was relevant for rather modest infrastructure volumes by modern standards.
Today, the infrastructures of large organizations not only consist of thousands of configuration units, which makes it impossible to effectively manage them manually, but are also hybrid, that is, in addition to physical configuration elements, they contain their own internal and external cloud resources with a high degree of change dynamics. Solving the task of managing such a disparate and rapidly changing database of configuration items is a major challenge for IT management.
Approaches to building and managing a CMDB
Manual
Manual entry of information into the CMDB on the one hand requires a significant investment of human time, and on the other hand leads to errors and inconsistent data.

This approach is relevant for small organizations with static infrastructure.
But just these organizations are among those who most likely do not need CMDBs at all. For modern corporations this option is definitely not suitable. It seems logical to use automation tools.
Discovery
Discovery is a specialized software that allows you to collect infrastructure data in an automated mode. The Discovery engine contains components to address devices connected to the corporate network. The network sends out requests to the equipment using various protocols, the equipment responds to the request with its identification information, and thus the CMDB is automatically generated.
Discovery automates the following tasks:
- identifies new CIs and adds them to the CMDB;
- updates configuration data;
- maintains versioning of configurations;
- forms a map of infrastructure elements, which, when data on interrelationships with services is entered, turns into a full-fledged resource-service model.
Semi-automated approach
Discovery CMDB software automatically collects data about the existing infrastructure. Missing data and relationships between elements are then manually entered.
Modern infrastructures are dynamic, they are constantly changing, accordingly, to keep the CMDB up-to-date, diskaveraging must be regular, and with a vast infrastructure, this is not a quick process. The logical solution is to run discovery during off-hours.
To use it effectively, it needs close integration with ITSM processes, so this mechanism is likely to be part of an ITSM solution. And if it is launched during working hours, it is highly likely that the system performance will slip, which is unacceptable.
It is possible when a diskaveraging took place at night and in the morning the developers deployed dozens of virtual machines, for example, for testing purposes. At this moment, due to lack of memory, an incident occurs on the physical host where these virtual machines are located. In the process of incident resolution we turn to the resource-service model and do not see the reasons, because our CMDB does not know about these virtual machines yet, and the next diskover is in a few hours. But by the time it starts, it is quite possible that these virtual servers will no longer exist because they have fulfilled their function and are no longer needed.
Thus we come to the conclusion that diskaveraging does not always solve the problem of data relevance in CMDB.
IaC – Infrastructure as Code
DevOps practitioners have presented us with new possibilities for infrastructure management.
Infrastructure as code is an approach that not only automates the deployment of infrastructure in a specific configuration, but also allows you to manage it quickly.
Software-defined infrastructure is the future that has already arrived.
The essence of IaC is that complete configurations are packed into containers that are deployed using scripts with those settings stored as code. Now there is no need to configure servers manually or even clone existing ones, as one administrator can maintain hundreds of such servers simultaneously.
Configurations are stored in CMDB in the form of code and are also managed using code. And since it is code, it can be tested without human intervention. With IaC we don’t need to go to the server and check if all libraries are installed, if all connectors are up, if all configuration meets our needs, etc. Instead, an automated test is written. If the test fails, the deployed infrastructure is removed in two clicks and a new deployment script is started.
With built infrastructure management processes as code, the deployed infrastructure data will always be up to date.
With IaC, the CMDB becomes a source of reference infrastructure data rather than an aggregator of infrastructure data.
Previously, we needed to discover a configuration item, recognize it, and commit information about it to the CMDB. With the use of infrastructure management as code, the situation is the opposite: we first create a model of the configuration item and then create any number of required configuration units as needed.
In the combination of autodiscovery and infrastructure-as-code management, an ideal is born: continuous CMDB generation.
Continuous approach to CMDB generation
Continuous discovery, IaC as a source of reference information and always up-to-date configuration, and in some aspects manual management (unfortunately you can’t do without it, but it is important that it is the minimum amount of operations necessary).

When all three components are combined, we get a CMDB with up-to-date data. And an up-to-date CMDB is a powerful tool in IT management.
How to build and manage a CMDB?
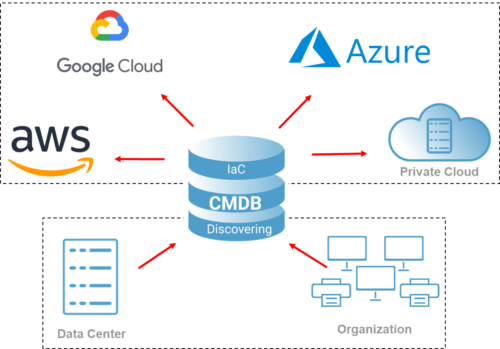
- Everything that resides in the cloud – must be managed within an “infrastructure as code” approach.
- Configuration units located in physical data centers – managed using a “continuous discovering” approach.
- Office infrastructure elements can be managed using continuous discovering and manually.
CMDBs must change. Approaches to their formation must change. Already today CMDBs should not just store data about accounted infrastructure elements and connections between them, but should be tightly integrated with hypervisors, orchestrators, dynamic configuration management systems.
At the same time, operations with CMDBs must be correctly and conveniently integrated into the processes associated with configuration management. CMDBs should become flexible and dynamic, generating objective value rather than being a source of problems.
SimpleOne SACM
The roadmap for the development of ITSM solutions on the SimpleOne platform includes all of the above approaches to populating and updating CMDB data. SimpleOne SACM (Service Asset and Configuration Management) will soon provide flexible, convenient and efficient tools for configuration and asset management.
SimpleOne SACM’s comprehensive business solution will include the modules:
- SimpleOne CMDB – CMDB module with continuous discovery tools, necessary components for organizing infrastructure-as-code (IaC) management and tools for forming and managing the resource-service model of the organization;
- SimpleOne ITAM – IT Asset Management Module
