If you manage enterprise IT in 2026, you know the daily grind: developers want to push code to production ten times a day, business stakeholders demand 99.99% uptime with a slashed budget, and your L1 support team is burning out from password reset requests.
In this high-pressure environment, running IT without strict ITSM processes is equivalent to flying blind. The Uptime Institute’s report confirms that downtime costs are reaching record highs. More than 50% of recent failures now exceed $100,000 in damages, and “catastrophic” outages costing over $1 million surged from 11% to 16% year-over-year. In today’s complex hybrid-cloud environments, these figures prove that a single process failure is no longer just an IT issue — it’s a major financial risk.
However, the industry is plagued by “process theater” — bureaucratic workflows designed to look good on an auditor’s clipboard but that paralyze actual operations.
In this guide we are going to look at the operational reality of managing IT services at scale. We will dissect how to implement processes that actually protect production environments, reduce Mean Time to Resolve (MTTR) without gaming the metrics, and balance the eternal conflict between delivery speed and infrastructure stability.
What Are ITSM Processes?
In the trenches, ITSM processes are your operational playbook. They are the standardized, repeatable sequences of actions that dictate how your IT department handles outages, fulfills user requests, introduces new code or hardware into the environment, and prevents future failures.
To truly grasp the ITSM meaning, you must stop viewing IT as a collection of servers and software. ITSM shifts the paradigm to managing services that the business consumes. A server is just hardware; “Corporate Payroll Access” is a service. ITSM processes are the rules of engagement that ensure that service remains available, secure, and cost-effective.
Without these processes, every P1 (Priority 1) outage becomes a chaotic scramble where engineers waste the first two hours just figuring out who is responsible for the failed node.
Why Are ITSM Processes Critical for Business in 2026?
The enterprise landscape in 2026 is unforgiving. You are likely supporting a Frankenstein architecture of legacy on-premise mainframes, multi-cloud deployments, and containerized microservices.
In this reality, ITSM processes are critical for survival:
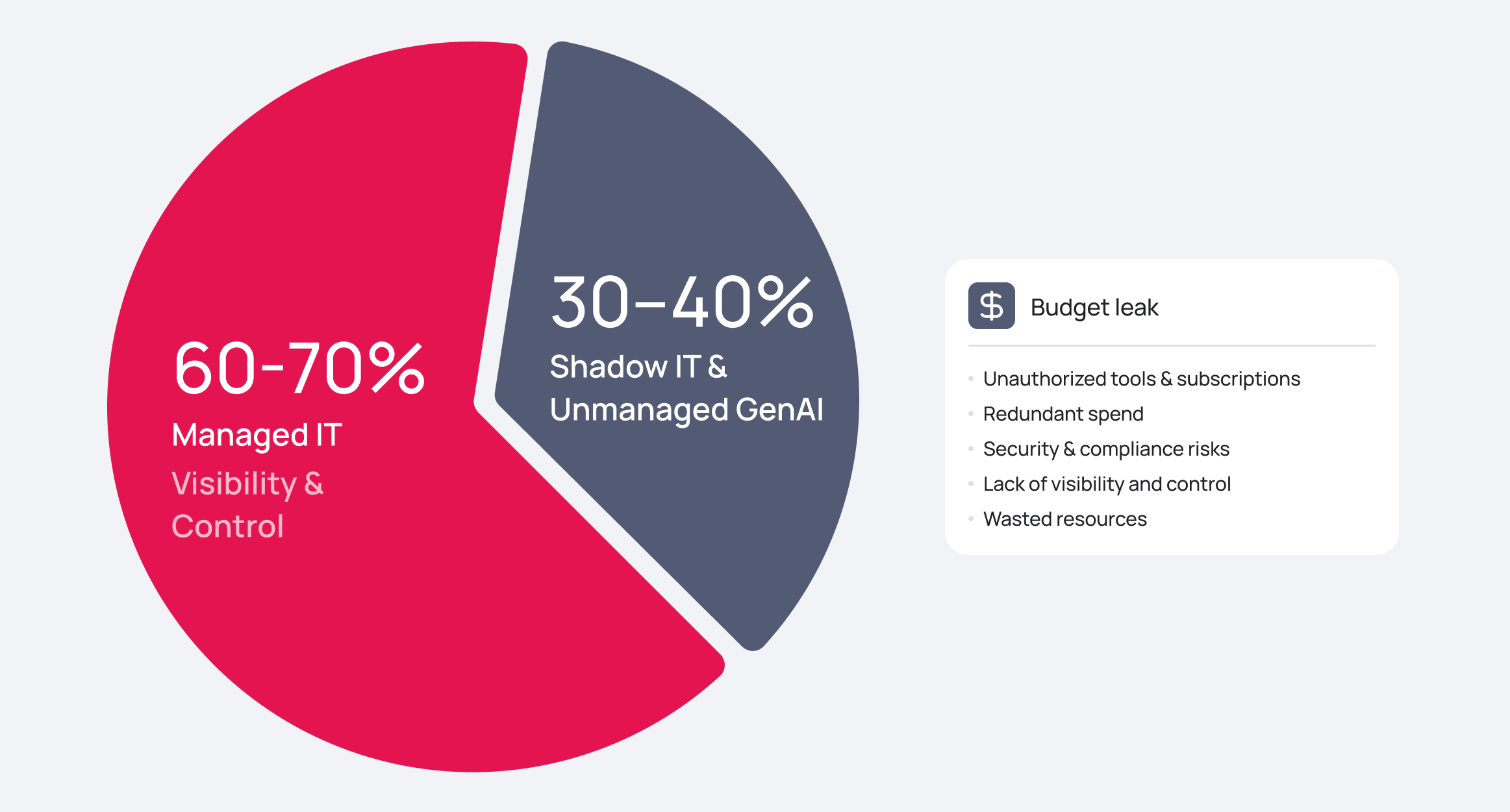
- Eliminating “Shadow AI” and Budget Leaks: Traditional Shadow IT already consumes between 30% and 40% of IT spending in large organizations. However, in 2026, this has evolved into a more dangerous form: Shadow AI. According to a 2025 Gartner report, 75% of organizations now face unmanaged GenAI use, creating “blind spots” that lead to catastrophic data leakage and unpredictable costs. Without a standardized service catalog and request fulfillment process, CIOs have zero visibility into which AI tools are processing sensitive corporate data.
- Protecting Uptime in CI/CD Environments: Developers use automated pipelines to ship fast. If Change Management processes aren’t integrated into the CI/CD pipeline as automated guardrails, a bad deployment will take down your revenue-generating apps during peak hours.
- Scaling Beyond IT: The modern business expects the same structured delivery from all departments. Mature IT organizations are leveraging enterprise ITSM platforms to extend these proven processes to HR, Facilities, and Legal, creating a unified corporate service model.
ITSM processes according to the ITIL
If we look at the textbook, ITIL 4 (Information Technology Infrastructure Library) officially transitioned away from the word “processes,” renaming them “practices.” This was done to emphasize that managing IT requires more than just workflows — it requires people, technology, and partner integration.
However, in the operational reality of a Service Desk, we still build, automate, and execute processes. While ITIL 4 outlines 34 distinct practices, trying to deploy all of them is a fast track to project failure. Enterprise survival relies on mastering the core transactional processes first.
7 Core ITSM Processes You Need to Know
To keep the lights on and the business running, you must establish strict governance over these seven areas.
1. Incident Management
The Goal: Put out the fire as fast as possible.
An incident is any unplanned interruption to an IT service. The Incident Management process dictates how you restore service.
The Reality: The priority here is speed, not perfection. If an ERP system goes down, Incident Management applies a workaround (e.g., rebooting the server, rolling back a patch) to restore access. Finding out why it crashed is a task for Problem Management.
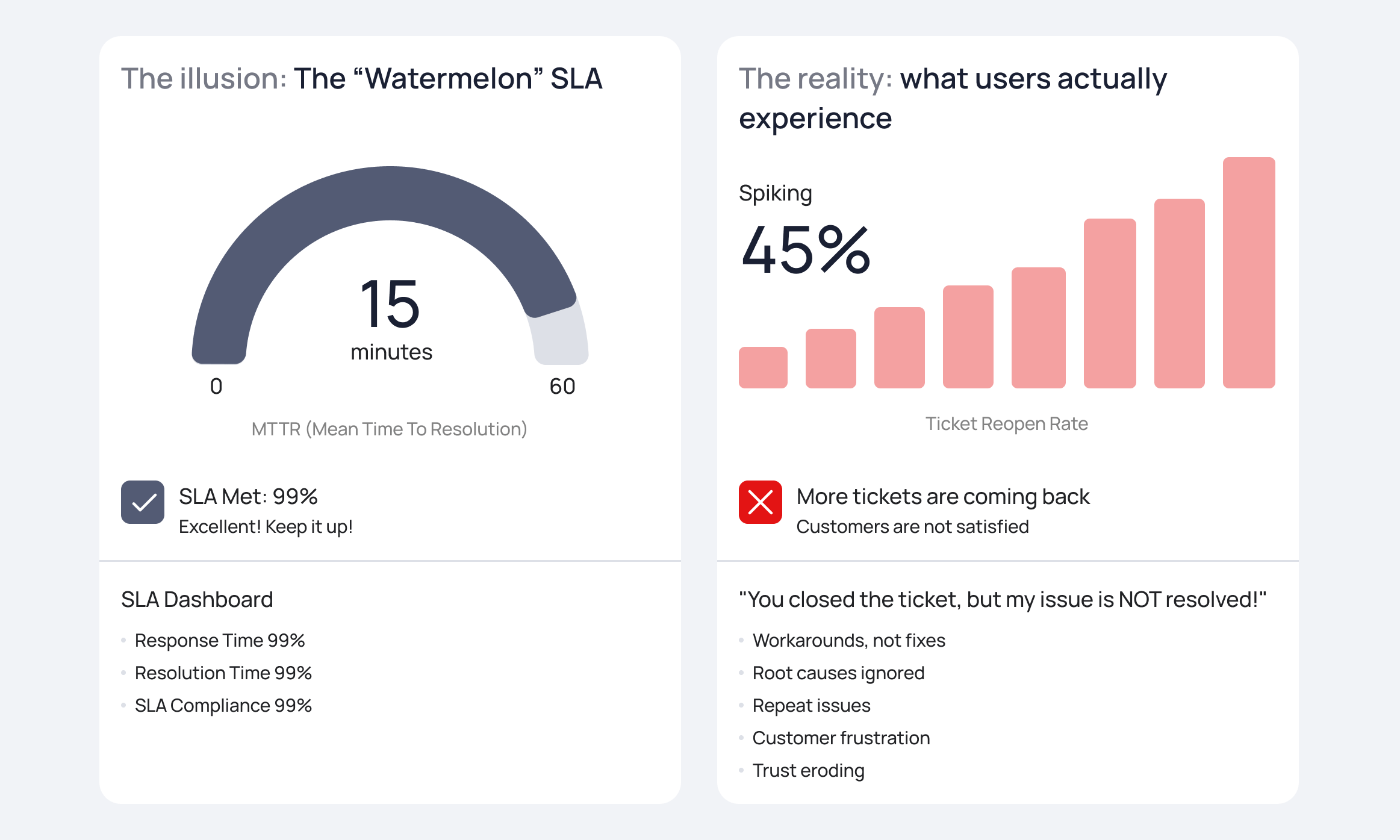
Insight: Do not just look at MTTR (Mean Time to Resolve). If MTTR is low but your Reopen Rate is high, your L1 agents are prematurely closing tickets to hit their KPIs without actually fixing the user’s issue. Furthermore, clear escalation paths are non-negotiable. If a P1 isn’t touched in 15 minutes, it must automatically route to the Shift Lead. Stop relying on L1 to manually hunt down L3 engineers in Slack at 3 AM.
2. Service Request Management
The Goal: Handle standard, pre-approved user requests efficiently.
This covers everything from “I need a new software license” to “Onboard a new employee.”
The Reality: This process must act as a shield for your L2 and L3 engineers. By automating Service Requests through a Self-Service Portal with clear approval workflows, you stop highly paid system administrators from wasting time manually provisioning email accounts. Do not attempt to build a massive 500-item catalog overnight. Start with a “Minimum Viable Catalog” — 5 to 10 high-volume requests to stop the chaos of free-text emails.
3. Problem Management
The Goal: Stop putting out the same fires. Find the root cause.
The Reality: This is the most neglected ITSM process because it requires time, and IT is always busy. Problem Management fails because it competes for the same engineering resources as Incident Management and Development. The trade-off is painful but necessary: you must intentionally allocate 10-15% of your L3 capacity specifically for root-cause analysis. If you do not dedicate engineering hours to fixing bugs, you will eventually go bankrupt on operational support costs.
4. Change Management
The Goal: Ensure that introducing new code, hardware, or configurations into the live environment doesn’t break existing services.
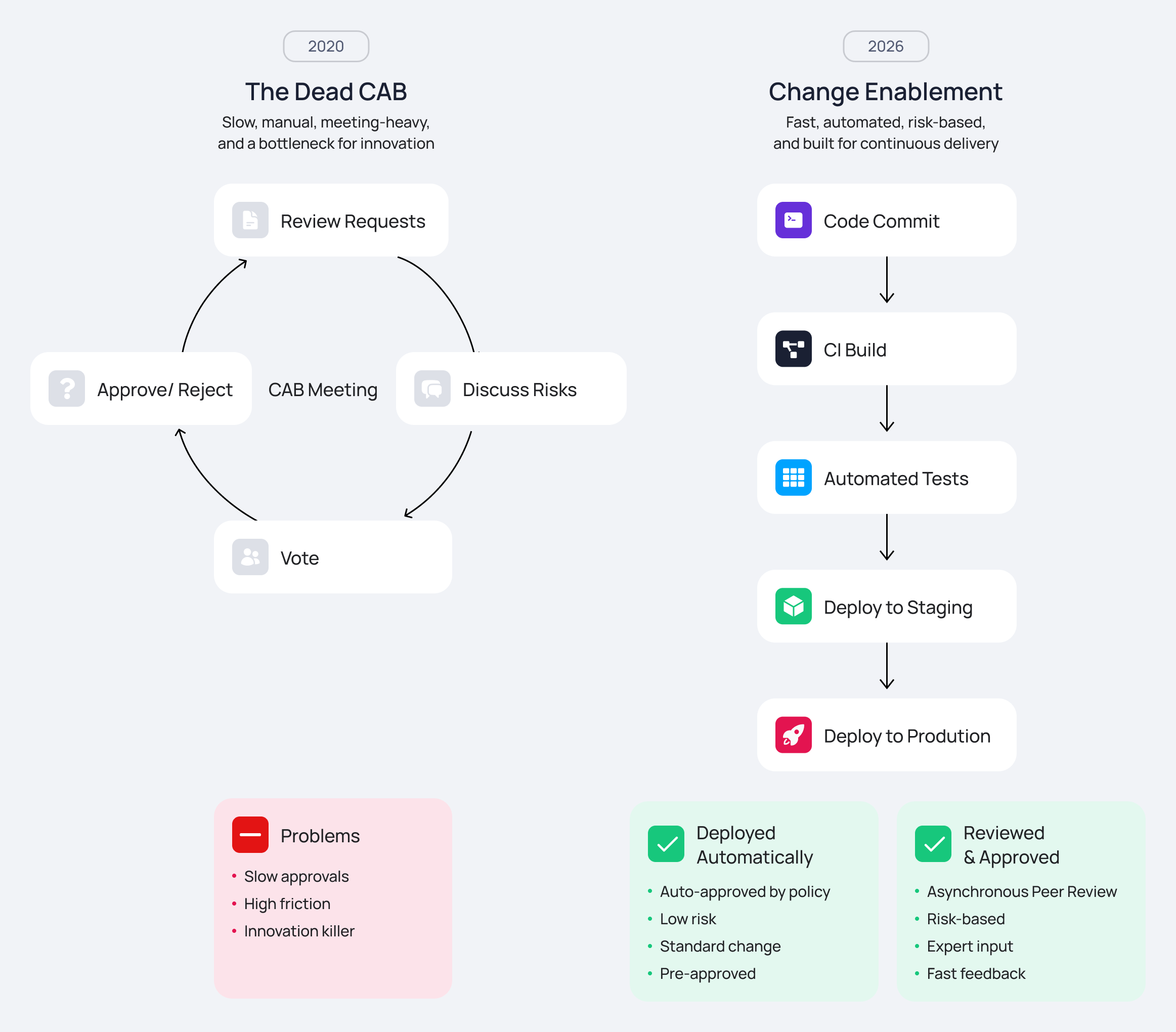
The Reality: This is where the biggest conflict in IT lives: Stability (Ops) vs. Speed (Dev). The traditional 20-person Change Advisory Board (CAB) meeting on Thursdays is dead. To survive in 2026, Change Enablement must focus on maximizing “Standard Changes” — low-risk, pre-approved changes that can be automated through pipelines. If you must have a CAB for compliance (PCI, SOX), make it asynchronous within the ITSM tool. Engineers should vote on changes via portal approvals, reserving synchronous meetings only for high-risk, cross-functional deployments.
5. Configuration Management
The Goal: Maintain an accurate map of your IT assets and how they depend on each other to deliver a business service.
The Operational Reality: The Configuration Management Database (CMDB) is never 100% accurate. If a vendor promises you a perfect CMDB, they are lying. The goal is to maintain 85-90% accuracy for critical business services. A classic operational failure occurs when L1 routes a P1 incident to the wrong database team because the CMDB showed an active dependency that was deprecated 6 months ago. MTTR blows up by 2 hours just finding the right team. This is why CMDB hygiene is a daily operational necessity, not a one-time project.
6. Knowledge Management
The Goal: Capture tribal knowledge and make it accessible.
The Reality: A good Knowledge Base (KB) is not just about user self-service; it is your primary defense against L1 agent turnover. In an environment where Service Desk turnover can hit 30% annually, a centralized internal KB is the only thing that accelerates new hire onboarding and slashes MTTR for junior engineers. By documenting Known Errors and their workarounds, L1 agents can resolve complex tickets without escalating.
7. Service Level Management
The Goal: Negotiate, monitor, and report on the quality of IT services provided to the business (SLAs).
The Operational Reality: This is about trade-offs. If the business demands a 99.99% uptime SLA for an application running on legacy, undocumented code, IT must present the financial cost required to achieve that (e.g., building redundant clusters, 24/7 on-call staffing). Beware of “Watermelon SLAs” — metrics that show green on the dashboard, but the business users are furious because the service is practically unusable.
Implementation of ITSM Processes
You cannot automate a broken process. When implementing ITSM processes, the “Lift and Shift” approach is fatal. Taking a chaotic email-forwarding workflow and forcing it into an expensive new platform will only yield expensive chaos.
The Implementation Playbook:
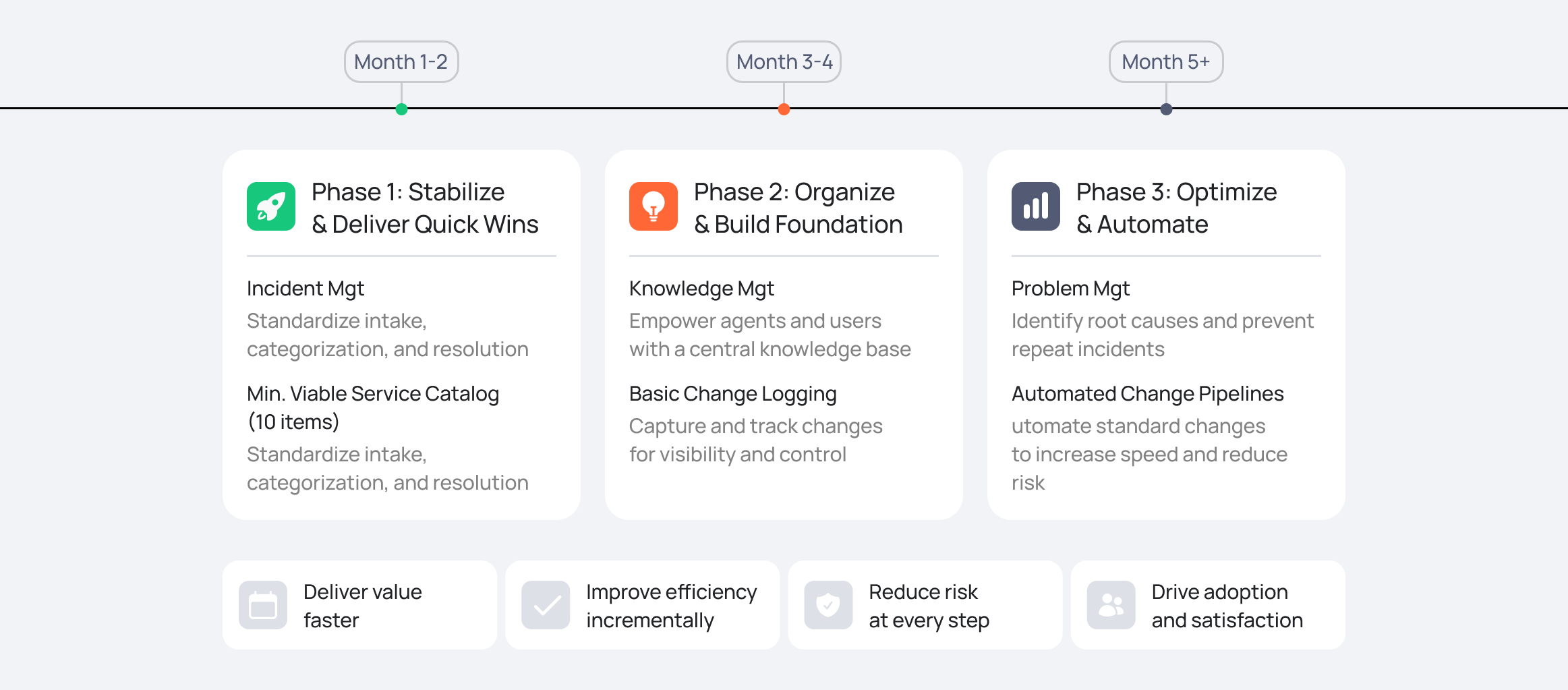
- Start Small (MVP): Begin with Incident Management and a Service Catalog with 10-15 high-volume request items. Do not touch Problem Management until L1 is stabilized. For Change Enablement, start with a Minimum Viable Process — implement just enough governance to log and authorize high-risk changes to protect production, but leave complex pipeline automation for Phase 2.
- Acknowledge the Legacy: You will have constraints. You cannot immediately automate legacy systems that lack APIs. Build manual manual tasks into the workflow for these edge cases while you plan their eventual retirement.
- Manage the Burnout: Implementing processes adds administrative overhead initially. L1/L2 engineers will resist filling out mandatory fields when the queue is burning. Strong executive sponsorship is required to push through this cultural friction.
- Define Escalation Matrices: Write explicit rules on when an incident moves from L1 to L2, and from L2 to L3 (or on-call duty). Vague escalations lead to ignored P1s in the middle of the night.
Software for ITSM Processes
Modern ITSM processes require an agile architectural foundation. In 2026, rigid, hardcoded legacy monoliths are a liability. If your administrators have to write custom scripts or hire external consultants just to add a new approval step or modify a form, your Total Cost of Ownership (TCO) will consume your budget.
When selecting an IT service management system, enterprise leaders are pivoting to platforms that balance strict governance with rapid adaptability.
This means prioritizing a Low-Code platform architecture (like а SimpleOne). A low-code foundation allows your internal business analysts to adjust workflows, SLAs, and forms visually in a matter of days.
However, enterprise IT requires a critical caveat: flexibility without governance equals chaos. If you let every department build their own workflows without a Center of Excellence (CoE) overseeing the architecture, your flexible platform will turn into a tangled mess of undocumented “spaghetti processes.”
The software must support strict Pro-Code discipline behind the scenes — such as version control, update sets, and separated Dev/Test/Prod environments. This ensures that while you can adapt processes quickly, you do not break production logic or compromise compliance regulations (PCI DSS, ISO 20000).
Conclusion
ITSM processes are not designed to create bureaucracy; they are designed to protect the business and make IT operations sustainable. They provide the framework to resolve a 3 AM outage methodically, prioritize the right development tasks, and justify IT budgets to the CFO.
Do not fall into the trap of process theater. A beautiful workflow diagram means nothing if your engineers bypass the system because it takes ten clicks to close a ticket. Align your processes with operational reality, choose a flexible platform that can evolve without vendor lock-in, and always remember: processes serve the business, not the other way around.
Frequently Asked Questions (FAQ)
What are ITSM processes?
They are structured, repeatable workflows used by IT teams to manage the end-to-end delivery of IT services. They dictate how IT responds to incidents, handles user requests, implements infrastructure changes, and maintains operational stability.
What is the difference between ITSM and ITIL?
ITSM is the actual practice of managing IT as a service within an organization. ITIL is a globally recognized framework — a library of best practices — that provides guidelines on how to execute ITSM effectively. ITSM is what you do; ITIL is a guidebook on how to do it.
Which ITSM process should I implement first?
Always start with Incident Management and Service Request Management. Establishing a clear channel for users to report broken items (Incidents) and request new items (Service Requests) immediately restores order, protects L2/L3 engineers from constant interruptions, and provides visible value to the business.
How long does ITSM implementation take?
For an enterprise environment, a realistic timeline is 6 to 12 months. This accounts for mapping legacy processes, sanitizing CMDB data, configuring complex approval routing, and, most importantly, the organizational change management required to train staff and shift corporate culture.
Can AI replace ITSM processes?
No. Generative AI and AIOps are powerful tools that can categorize tickets, analyze logs to predict outages, and draft Knowledge Base articles. However, AI requires structured data and predefined rules to function safely. GenAI in 2026 is excellent at automating L0 (ticket classification, summarizing 50-message email chains for L2), but it will not fix a database deadlock at 3 AM. Without mature, underlying ITSM processes defining access, approvals, and escalation paths, AI will simply execute flawed logic at a faster speed.
